
(Nobody actually reads this blog.)
Last week (for the purposes of narrative, this is accurate enough) Commie released Kyousougiga. All’s fine and well, right? Except that’d be too good to be true. The whole point of making a blog post is to describe something that’s not fine and well, since fine and well things are the norm and hence not really worth blogging about.
First, you should already know what telecine is. What the sources for Kyousougiga currently have all follow this clean-clean-blended-blended-clean pattern. Sounds familiar? Right, it’s almost exactly like the pattern you get for telecined sources, except instead of combing you have blending. Unlike telecine, we don’t have clean fields to match from. However, what we do have are clean frames to calculate against. For various definitions of “clean”.
So anyway, RHE basically went :effort: on this and did deblending. And he also said I could do all subsequent episodes. I decided to take a look at the first episode just to get a feel of what it’d be like.
Suppose we somehow had access to the original, pre-blending source. Let 



Going by the above ansatz about how blending works, 


Something I was unaware of when I started was that the whole video was actually constant-pattern, so I could very well have specified a single pattern to begin with. What I ended up doing was to automatically generate sections with scxvid, then to find the phase that minimises the mean absolute difference within a section. (Idea shamelessly stolen from tp7’s script for Jintai.) This still had blending detection errors, but it’s still useful to check that the video has constant-pattern blending.
Now that phase detection is settled, how exactly should 

One thing I thought of randomly when I was doing AKB0048 encodes (which will never be released anyway) was to take three sources, then instead of just averaging them (which was a great improvement already), I Repair()’d them against each other, then averaged them. The encode for the OP is on that XDCC bot, so you can see for yourself. It’s actually pretty decent for a TV encode, if I may say so myself. (The idea of actually merging together multiple sources came from __ar’s TV encodes for Fate/zero.)
If you actually read this blog (who am I kidding), the Signal Graph music video had a dupe once every five frames, but doing a repair-average had practically no difference (to the naked eye or with histogram-luma-vision) over a plain average (which was itself a nigh-placebo improvement), so I simply didn’t waste CPU time doing that for Signal Graph.
Back to the main topic, we should actually scrap the Gaussian iid artifacts model. The artifacts are correlated with the source; edges typically have stronger artifacting, for example. Let 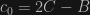





So there we have it.
Now, that’s not actually the end of the story. There were three streams for Kyousougiga, but I only managed to rip the Nico and YouTube streams (since ripping methods for those are pretty well known). The Nico stream was only 288p, but it looked a lot less eyecancer than the YouTube 480p stream. See: comparison. (That uses the plain average deblend for both screenshots, not the repair-average deblend; Nico was upscaled with nnedi3_rpow2.) Of course, there are some scenes where the postage-stamp resolution is pretty obvious, but at least the lack of obvious edge noise makes up for that!
That said, NyaaTorrents has a policy against upscales of web streams. We’ll see how this plays out.
I downloaded EveTaku’s release too to check. It was unexpectedly… bleh. So much for “raw has been touched up a bit to remove blended frames“. This is probably going to be extremely hypocritical, but I’ll criticise their video quality anyway. Around 2:53 there’s a lantern, which broke their blending phase detection (of whatever script they’re using to deblend), and funnily enough they typeset to the jerky (on their encode) text on the lantern with what I presume is Mocha. (Typesets not sorted by time etc., but I’m not herkz.) Transferring it to my properly deblended encode made the Japanese text move smoothly and the typesetting move… jerkily. Good job :effort:ing on a broken encode, I’m sure your leechers appreciate that.
And on a closing note, if NT changes its policies on web stream upscales, this will be v2’d for Commie with my encode. Encode’s currently on that same XDCC bot with both Commie and EveTaku’s subs muxed (without any shifting, so loldesync).
